Registry
Overview
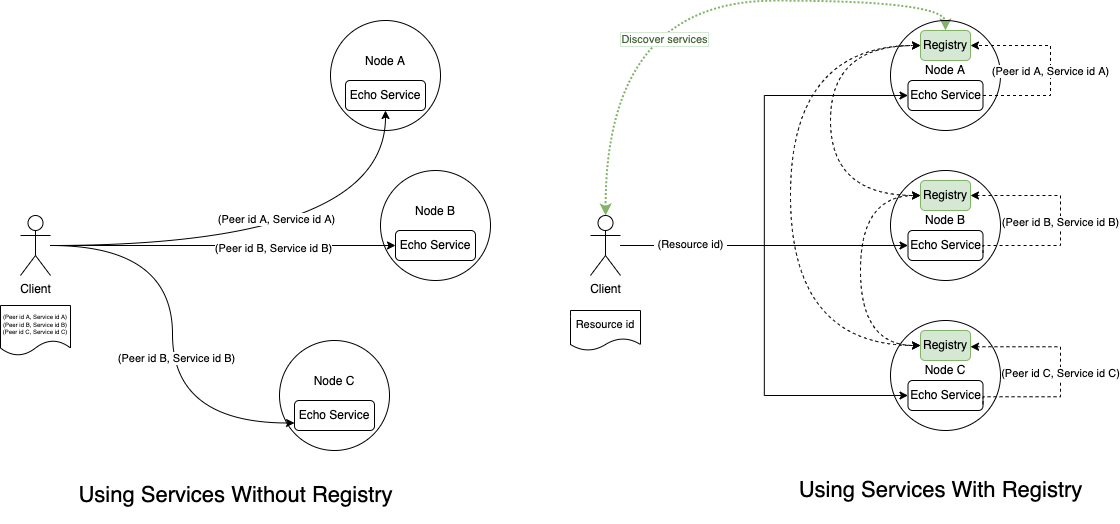
There are many services in the network on different peers and should be a way to find and resolve them in runtime without prior knowledge about exact service providers. This approach gives robustness and flexibility to our solutions in terms of discovery, redundancy and high availability.
In centralized systems, we can have centralized storage and routing, but in p2p decentralized environments, this problem becomes more challenging. Registry is our view on the solution for this problem.
Why is it important?
Scalability, redundancy and high availability are essential parts of a decentralized system, but they are not available out of the box. To enable these, information about services should be bound with peers providing them. Also, these networks are frequently changing and should be reflected and resolvable in runtime to provide unstoppable access. So you should have some decentralized protocol to update and resolve information about routing, both global and local.
What is it?
Registry is available (built-in) on every Fluence node. It provides service advertisement and discovery. This component creates relationships between unique identifiers and groups of services on various peers. So service providers can join or disconnect during runtime and be discoverable in the network.
However, Registry is not a plain KV-storage. Instead, it is a composition of the Registry service for each network participant and the scheduled scripts maintaining replication and garbage collection.
If you want to discover a group of services on different peers without prior knowledge in runtime, you should register a Resource. A resource is a group of services or peers united by some common feature. Please notice that resource lifetime is ~24 hours. However, if the resource has been accessed recently, it will not be garbage-collected for the next 24 hours from the last access.
A combination of service_id and peer_id represents a service Provider.
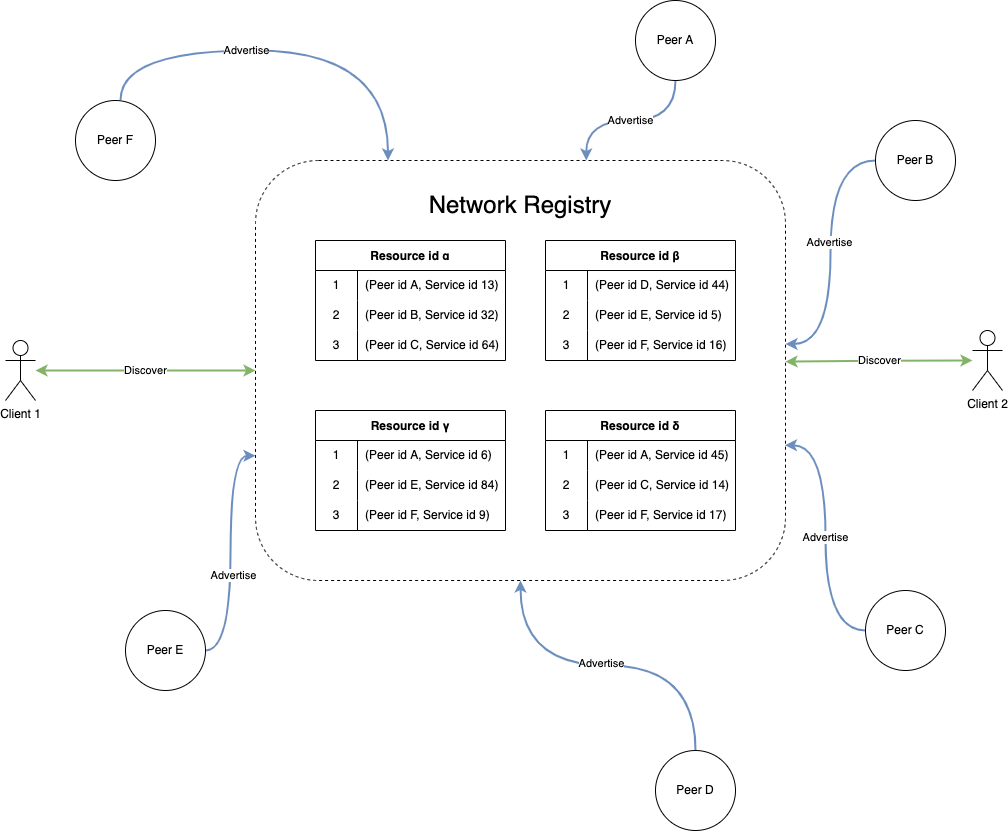
There are two types of providers depending on a peer this service operates on. Node Providers correspond to a full-featured Rust node and the rest of Providers — to a JS peer/client. And a record for any provider should be renewed every 24 hours to avoid garbage collection.
As for now, every resource is limited by number of providers 32 it can hold, disregarding records for the node services. So local services have no limitation for registration in the local registry. Other providers' records are ranked by peer weights in the local TrustGraph instance. So locally every node has a list of the most trusted service providers. "Trusted" means that in terms of TrustGraph, a service provider complies with requirements defined by node owner.
There is no permissions management at the moment, but in the coming updates, a resource owner will provide a challenge to check against.
How to Use it in Aqua
How to import
import "@fluencelabs/registry/resources-api.aqua"
import "@fluencelabs/registry/registry-service.aqua"
func my_function(resource_id: string) -> []Record, *Error:
result, error <- resolveProviders(resource_id)
<- result, error
How to create Resource
createResource(label: string) -> ?ResourceId, *ErrorcreateResourceAndRegisterProvider(label: string, value: string, service_id: ?string) -> ?ResourceId, *ErrorcreateResourceAndRegisterNodeProvider(provider_node_id: PeerId, label: string, value: string, service_id: ?string) -> ?ResourceId, *Error
Let's register a resource with the label sample by INIT_PEER_ID:
func my_resource() -> ?ResourceId, *Error:
id, error <- createResource("sample")
<- id, error
createResourceAndRegisterProviderandcreateResourceAndRegisterNodeProviderare the combination of resource creation and provider registrationlabelis a unique string for this peer id- creation is successful if the resource id returned
*Erroraccumulates errors from all affected peers
How to register Provider
registerProvider(resource_id: ResourceId, value: string, service_id: ?string) -> bool, *ErrorcreateResourceAndRegisterProvider(label: string, value: string, service_id: ?string) -> ?ResourceId, *Error
Let's register local service greeting and pass some random string like hi as a value:
func register_local_service(resource_id: string) -> ?bool, *Error:
success, error <- registerProvider(resource_id, "hi", ?[greeting])
<- success, error
valueis a user-defined string that can be used at the discretion of the user- to update the provider record, you should register it one more time to create a record with a newer timestamp
- to remove the provider you should stop updating it
- you should renew the record every 24 hours to keep the provider available
How to register Node Provider
registerNodeProvider(provider_node_id: PeerId, resource_id: ResourceId, value: string, service_id: ?string) -> bool, *ErrorcreateResourceAndRegisterNodeProvider(provider_node_id: PeerId, label: string, value: string, service_id: ?string) -> ?ResourceId, *Error
Let's register service echo hosted on peer_id and pass some random string like sample as a value:
func register_external_service(resource_id: string, peer_id: string) -> ?bool, *Error:
success, error <- registerNodeProvider(peer_id, resource_id, "hi", ?[greeting])
<- success, error
- the record will not be garbage-collected from the provider's node, but it is better to update it every 24 hours. In the following updates renewing process will be handled by the node with scheduled scripts
How to delete Node Provider
removeNodeFromProviders(provider_node_id: PeerId, resource_id: ResourceId)Let's remove node provider's record from target node:
func stop_provide_external_service(resource_id: string, peer_id: string):
removeNodeFromProviders(peer_id, resource_id)
- it will be removed from the target node and in 24 hours from the network
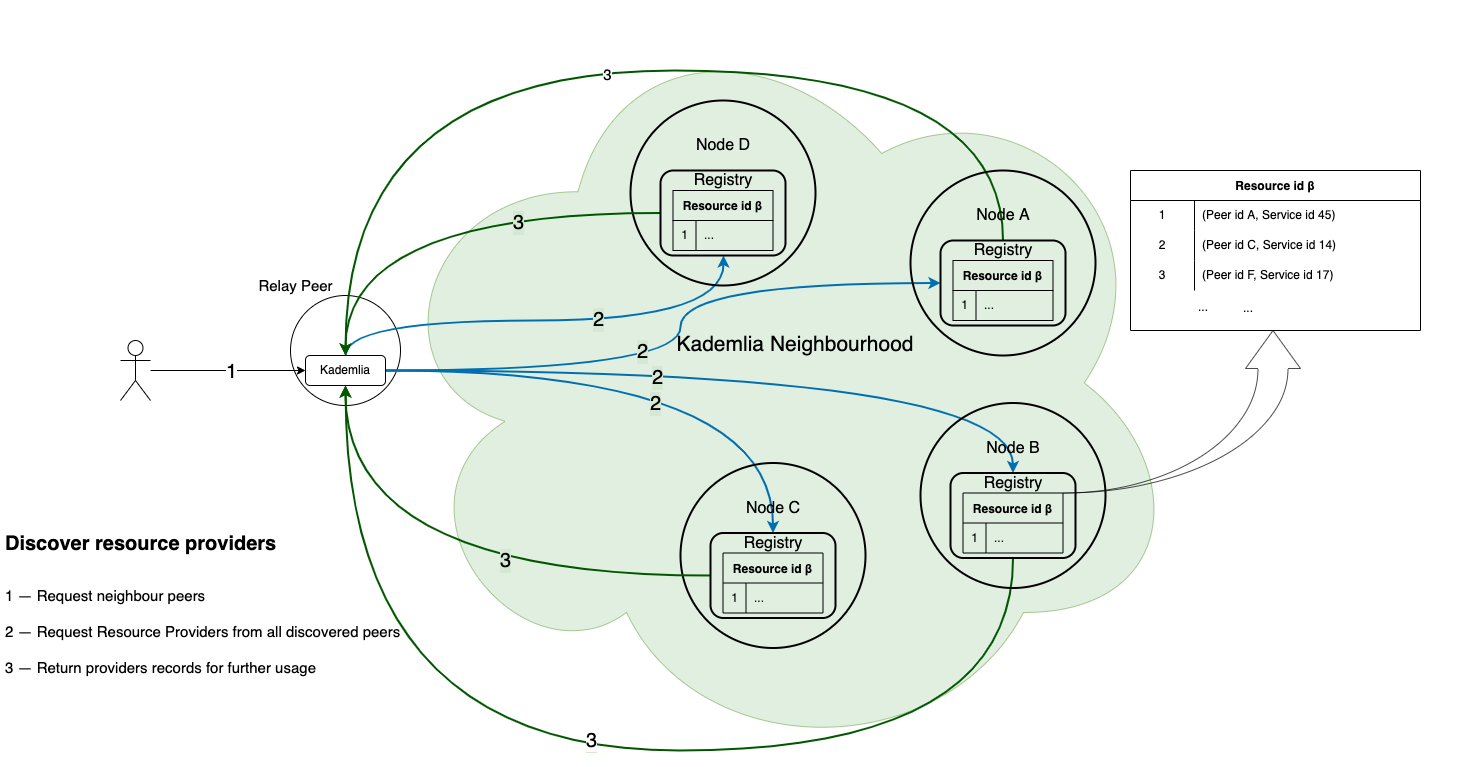
How to resolve Providers
resolveProviders(resource_id: ResourceId, ack: i16) -> []Record, *Error
Let's resolve all providers of our resource_id:
func get_my_providers(resource_id: string, consistency_level: i16) -> []Record, *Error:
providers, error <- resolveProviders(resource_id, consistency_level)
<- providers, error
ackis a characteristic that represents min number of peers who asked for known providers
How to execute a callback on Providers
executeOnProviders(resource_id: ResourceId, ack: i16, call: Record -> ()) -> *Error
func call_provider(p: Record):
-- topological move to a provider via relay
on p.peer_id via p.relay_id:
-- resolve and call your service on a provider
...
Op.noop()
-- call on every provider
func call_everyone(resource_id: String, ack: i16):
executeOnProviders(resource_id, ack, call_provider)
- it is just a combination of
resolveProvidersandforloop through records with callback execution - it can be useful in case of broadcasting events on providers
- look in the docs for more detailed example
Notes
You can redefine REPLICATION_FACTOR and CONSISTENCY_LEVEL.
Use cases
Services discovery
Discover services without prior knowledge about exact peers and service identifiers.
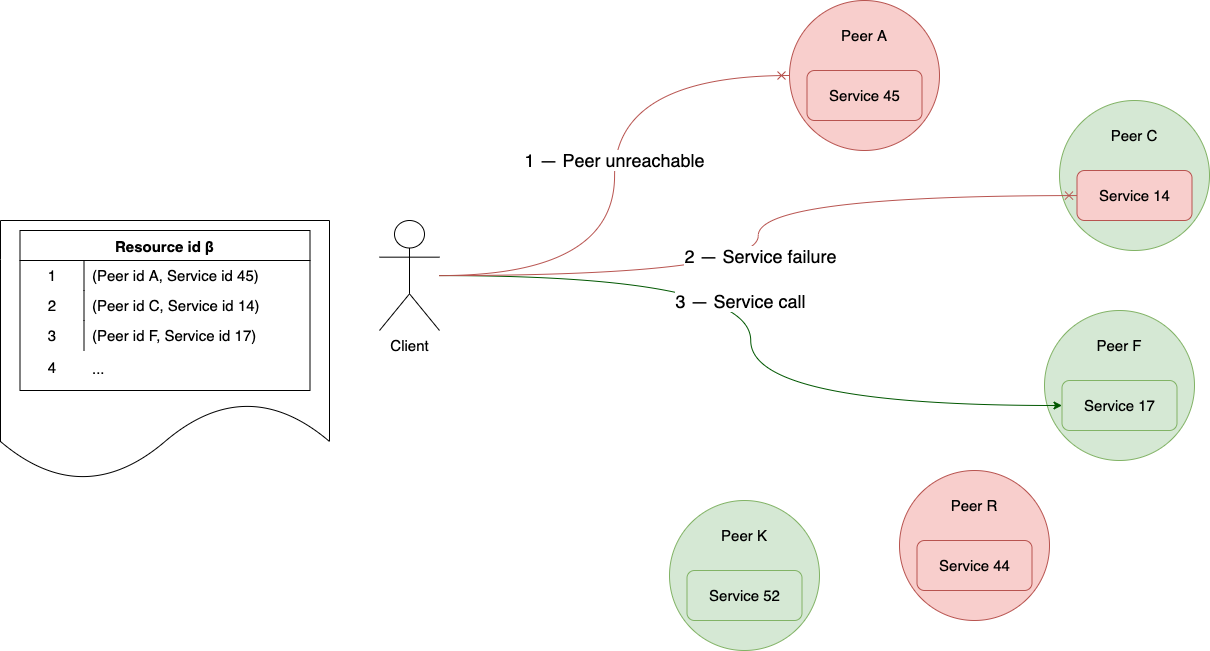
Service high-availability
Service provided by several peers still will be available for the client in case of disconnections and other providers' failures.
Subnetwork discovery
You can register a group of peers for a resource (without specifying exact services). So you "tagging" and group the nodes to create a subnetwork.
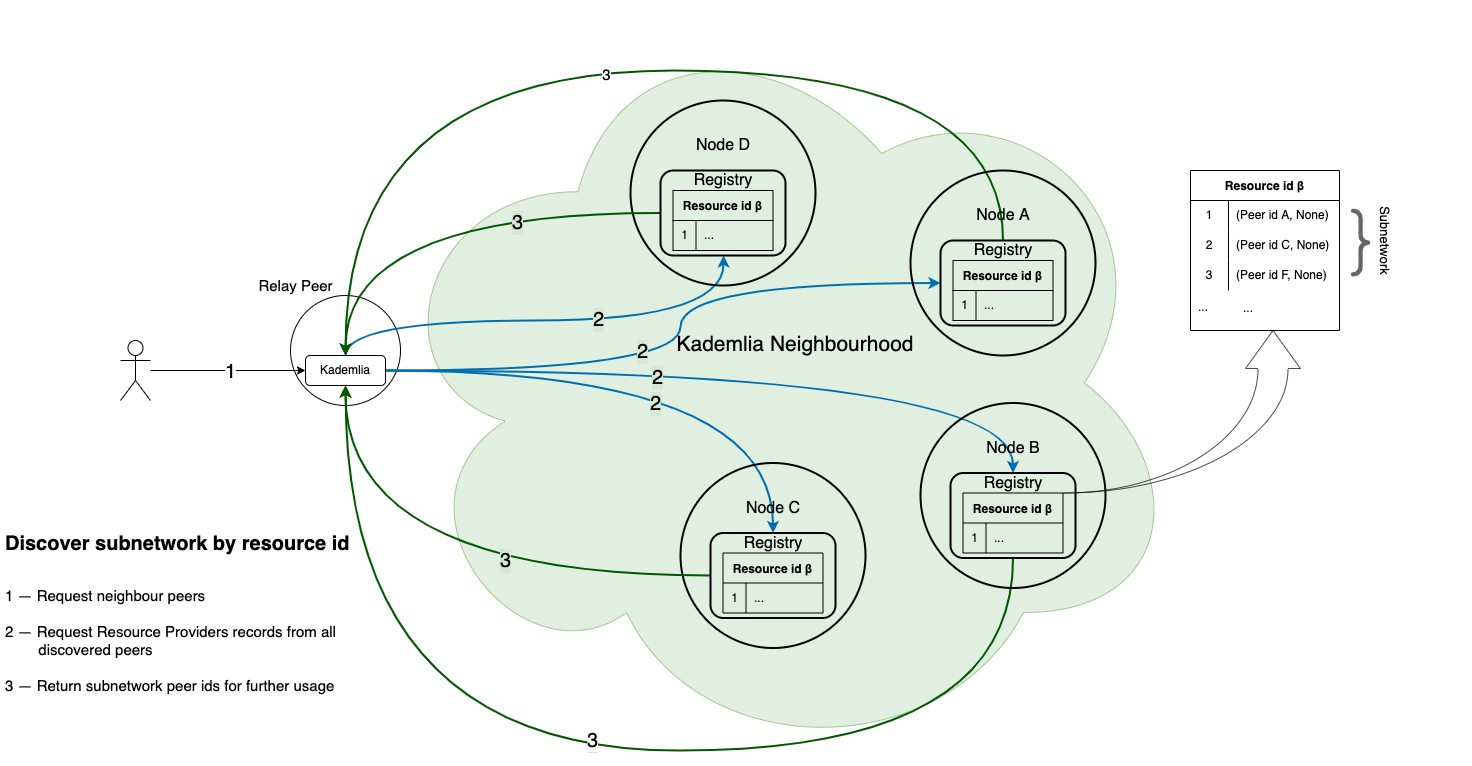
Load balancer
If you have a list of service providers updated in runtime, you can create a load-balancing service based on your preferred metrics.
API
API is defined in the resources-api.aqua module. API Reference will soon be available in the documentation.